

超越摩爾-存算一體架構探究
一、超越摩爾,人工智能時代需要新的芯片架構
目前市面存在的基于CPU、GPU等的計算系統(tǒng)都是基于馮諾依曼結構,其運算與存儲部件是分離的,進行計算時,計算單元需要將數(shù)據(jù)從存儲單元中提取出來,處理完成后再寫回存儲單元,這種結構導致了密集數(shù)據(jù)計算時需要在存儲部件與計算部件傳輸大量數(shù)據(jù),這就造成計算速度受到數(shù)據(jù)傳輸帶寬限制,同時引起功耗增加,限制了計算系統(tǒng)的性能提升。另一方面,現(xiàn)有的CPU、GPU等處理器都是使用數(shù)字電路實現(xiàn)計算功能,因而需要大量的計算資源,這也限制了可以達到的計算并行度以及計算速度。
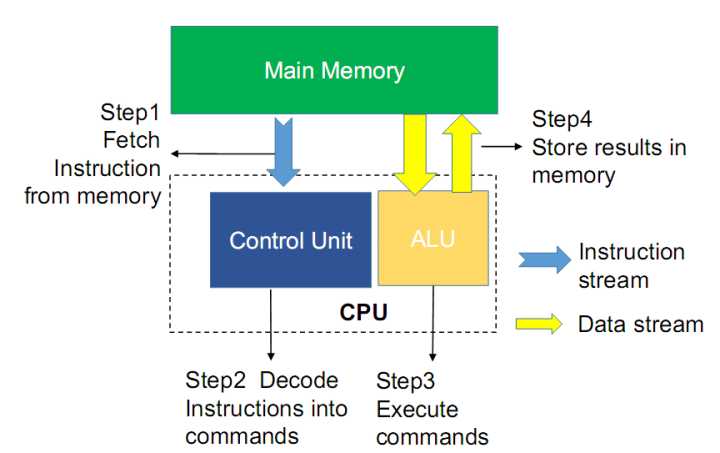
圖1 馮諾依曼架構圖
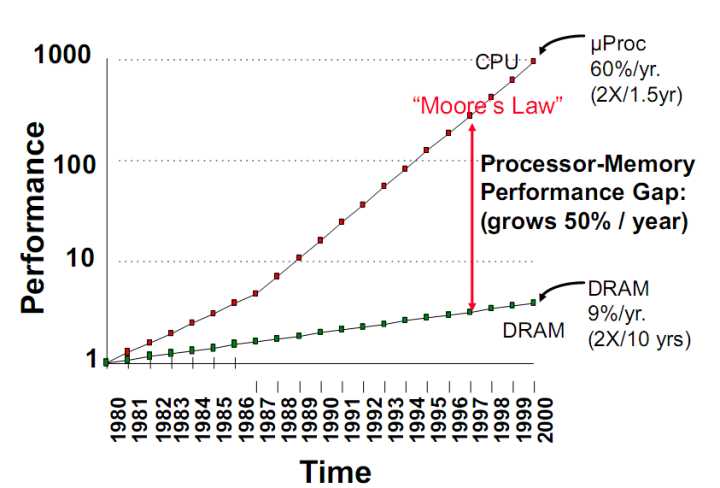
圖2 存儲墻剪刀叉
造成“存儲墻”的根本原因是存儲與計算部件在物理空間上的分離。從圖2中可以看出,從 1980年到 2000年,兩者的速度失配以每年 50%的速率增加。為此,工業(yè)界和學術界開始尋找弱化或消除“存儲墻”問題的方法,開始考慮從聚焦計算的馮諾依曼體系結構轉(zhuǎn)向聚焦存儲的“計算型存儲/存算一體/存內(nèi)計算”。
今年年初阿里達摩院發(fā)布了2020年十大科技趨勢,它認為存算一體是突破AI算力瓶頸的關鍵技術。因為利用存算一體技術,設備性能不僅能夠得到提升,其成本也能夠大幅降低。
馮諾伊曼架構的存儲和計算分離,已經(jīng)不適合數(shù)據(jù)驅(qū)動的人工智能應用需求。頻繁的數(shù)據(jù)搬運導致的算力瓶頸以及功耗瓶頸已經(jīng)成為對更先進算法探索的限制因素。類似于腦神經(jīng)結構的存內(nèi)計算架構將數(shù)據(jù)存儲單元和計算單元融合為一體,能顯著減少數(shù)據(jù)搬運,極大提高計算并行度和能效。計算存儲一體化在硬件架構方面的革新,將突破AI算力瓶頸。
二、計算型存儲/存算一體研究現(xiàn)狀
隨著3D堆疊技術的發(fā)展,以及新型非易失性存儲器器件的日益成熟,面向人工智能算法的大數(shù)據(jù)應用需求,計算型存儲/存算一體逐漸受到了工業(yè)界和學術界的關注。
目前,已經(jīng)有很多廠商和研究機構開始進入計算型存儲/存算一體領域,例如,INTEL、IMB和三星等廠商紛紛推出實驗型架構,一些研究機構也開始基于新器件新材料提前展開研究工作。
根據(jù)存儲器件的存儲易失性分類,計算型存儲/存算一體的實現(xiàn)主要聚焦在兩類存儲上:
1)基于易失性的SRAM或DRAM構建;
2)基于非易失性的相變存儲器PCM、阻變存儲器/憶阻器ReRAM、浮柵器件和閃存FLASH構建。
2.1 基于易失性存儲SRAM和DRAM的計算型存儲/存內(nèi)計算
易失性存儲器SRAM和DRAM工藝成熟,是目前商業(yè)化的主要存儲器產(chǎn)品。因此,很多的廠商和研究機構開始基于SRAM和DRAM展開存內(nèi)計算的研究。但是,目前這種計算型存儲/存內(nèi)計算存在一定的問題:
1)由于目前的存內(nèi)計算還處于實驗階段,存儲器廠商對工藝和制程的約束,大多數(shù)的研究都是在SRAM和DRAM的靈敏放大器端做工作,無法深入到存儲單元實現(xiàn)存儲和計算的完全耦合;
2)目前的計算型存儲/存內(nèi)計算基本上智能支持邏輯操作和無進位的計算,對于存儲單元間的信息交互還額外需要計算邏輯和控制邏輯的支持。
2.2 基于非易失性存儲器的新型計算型存儲/存算一體
非易失性存儲器在最近十幾年得到了飛速的發(fā)展,包括自旋矩磁存儲器STTRAM,相變存儲器PCM、阻變存儲器RRAM等。工業(yè)界和商業(yè)界已經(jīng)發(fā)布了眾多容量達到Gb量級的產(chǎn)品,Micon在2010年發(fā)布了45nm工藝的1Gb的PCM,三星2012年推出了20nm工藝的8Gb PCM,隨后在2015年Micron聯(lián)合三星一起推出了27nm的16Gb conductive bridge (CBRAM, 一種特殊的RRAM)。 同年, Micron和Intel共同發(fā)布了128Gb 3D XPoint 技術。2013年,Toshiba聯(lián)合Sandisk發(fā)布了24nm工藝的32Gb RRAM。
隨著非易失性存儲器產(chǎn)品的不斷成熟,容量不斷增大,研究者開始考慮基于非易失性存儲器構建存儲系統(tǒng)的可能性。同時,由于非易失性存儲器對計算和存儲的天然融合性,很多的研究和產(chǎn)品開始朝著基于非異失性存儲器的計算型存儲/存算一體發(fā)展。
1)相變存儲器相變存儲(PCM)是基于硫?qū)倩锊AР牧希茉谑┘雍线m電流時將介質(zhì)從晶態(tài)變?yōu)榉蔷B(tài)并再變回晶態(tài),基于材料所表現(xiàn)出來的導電性差異來存儲數(shù)據(jù)。
2)基于阻變存儲器ReRAM/憶阻器的計算型存儲/存算一體憶阻器最早由美國柏克萊大學的蔡少棠于1971年提出。憶阻器是一種有記憶功能的非線性電阻,其電阻會隨著流過的電路而改變。在斷電之后,即使電流停止了,電阻值仍然會保持下去,直到反向電流通過,它才會返回原狀。所以,通過控制電流變化可以改變其阻值,例如將高阻值定義為1,低阻值定義為0,從而實現(xiàn)數(shù)據(jù)存儲功能。2010年惠普實驗室再次宣布憶阻器具有布爾邏輯運算功能,這意味著計算和存儲兩大功能可以再憶阻器上合為一體,可能從根本上顛覆傳統(tǒng)馮諾依曼架構奠定了器件基礎。
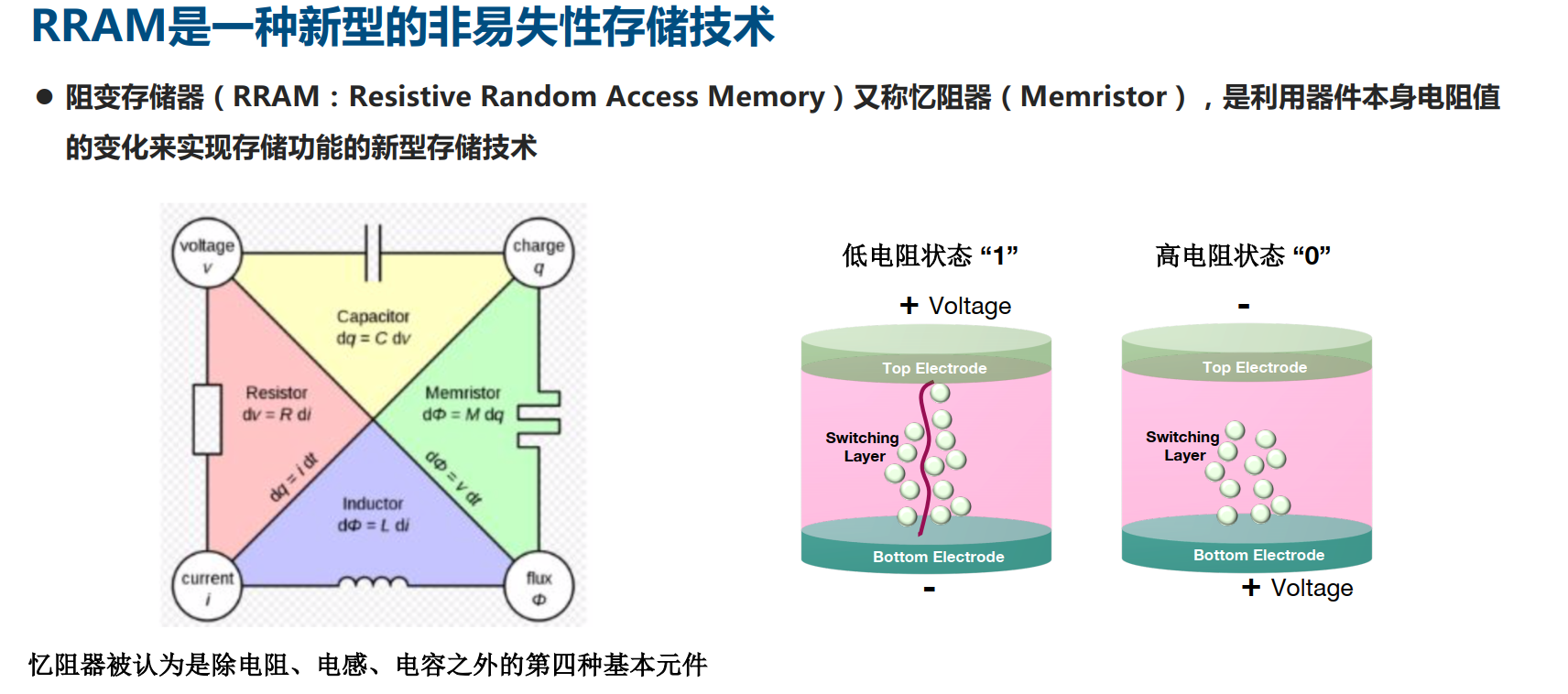
3)基于浮柵器件/Flash的計算型存儲/存算一體
浮柵器件工藝成熟,編程時間10-1000ns,可編程次數(shù)10^5,存儲陣列大,實現(xiàn)量產(chǎn)運算精度高,密度大,效率高,成本低。適合深度學習和人工智能應用。
目前基于閃存的計算型存儲/存算一體的是一家存算一體芯片設計公司,知存科技。閃存的存儲單元為三端器件,知存科技利用這一特點,基于NOR Flash構建了存算一體芯片。把乘數(shù)直接存入存儲單元內(nèi),再把數(shù)值輸入到閃存的陣列之中。每個單元都進行乘法,最后通過一條路徑求和,就可以達到存算一體的效果。乘法計算的方式是通過類似模擬電路的電流鏡方式。輸入電流轉(zhuǎn)換成電壓耦合到Flash晶體管的控制柵上,F(xiàn)lash晶體管的輸出電流等于輸入電流和存儲的權重相乘。加法的計算方式類似于并聯(lián)電路電流求和。具體的實現(xiàn)細節(jié)并未被披露出來,目前還未知其內(nèi)部的設計。根據(jù)宣稱,2016 和 2017年知存科技的 CTO 曾做出了多個樣品,最高峰值運算效率為40TOPS/W,平均值為 10TOPS/W。
三、結語
雖然存算一體技術方向廣受認可,英特爾、ARM、微軟等公司也均參與到該技術方向的投資,也有知存科技、閃億半導體、新億科技、智芯微電子等多家公司給出了可行的存算一體解決方案,但有一個不爭的事實是,沒有一家公司的存算一體技術解決方案受到廣泛的市場認可。
隨著AI需求的演進,可以相信的是,產(chǎn)業(yè)界會對芯片內(nèi)部相應優(yōu)化,通過調(diào)整設計架構,使其更好地支持現(xiàn)有網(wǎng)絡支持,可配置性更多,對新型網(wǎng)絡效率更高,整體芯片面積也變得更小。
存算一體畢竟是一個創(chuàng)新芯片架構,缺乏成熟的EDA工具、測試工具和應用層適配軟件,量產(chǎn)步驟還夠不成熟。不同于傳統(tǒng)芯片直接將量產(chǎn)步驟交由晶圓廠來完成,存算一體芯片的量產(chǎn)步驟需要芯片設計公司和晶圓廠一起來探索和建立。對于致力于推進存算一體的創(chuàng)業(yè)AI芯片公司,如何找準芯片應用行業(yè)方向,需求落地場景,如何融入產(chǎn)業(yè)需求,如何推進量產(chǎn)是接下來需要面對和解決的核心難題。
聯(lián)系電話:0755-26920764 辦公地址:深圳市南山區(qū)粵海街道大沖商務中心B座3106 聯(lián)系郵箱:xmxp@irunvc.com | 
掃一掃,關注我們 |